
Графический формат pdf является не только одним из самых популярных форматов в котором читают всевозможные книжки, журналы и т.д., но и так же, пожалуй, самым удобным форматов в котором можно отсканировать всевозможные тексты для их дальнейшего распознания и работы с ними. Тем более что большинство современных сканеров и мобильных приложений преобразуют сканированные копии текстов сразу в PDF формат.
Для того, чтобы распознать текст из pdf легко и быстро, можно воспользоваться бесплатной программой PDF-XChange Viewer. Сама по себе программа предназначена для просмотра файлов в pdf формате, однако у нее есть одна очень полезная функция, которая отличает эту программу от своих собратьев, это возможность распознавать текст.
И так, чтобы распознать текст из pdf следует после установки и запуска программы, на верхней панели инструментов нажать на кнопку OCR. Открывается окно настройки распознавания текста.
Первоначально в PDF-XChange Viewer русского языка для распознавания текста не установлено и поэтому, его надо дополнительно установить из дополнительного языкового пакета. Языковой пакет запускается из .exe файла двойным кликом по нему, в появившемся установочном окне следует выбрать нужным нам язык (естественно ставим галочку на против русского, ну или какого ни будь другого европейского языка если угодно) и устанавливаем пакет языков на компьютер.
После установки пакета перезагружаем программу и уже в меню «основной язык» устанавливаем русский язык.
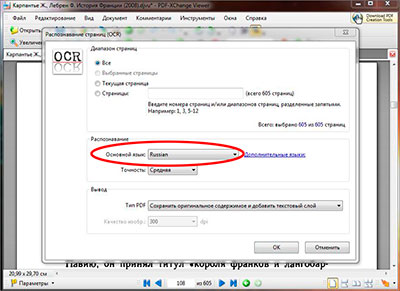
После того как основной язык выбран, там же в настройках распознавания текста, так же можно выбрать сколько будет распознано страниц файл. Если страниц в pdf файле не много, то его можно распознать целиком, если же станиц очень много и они все не нужны, то для сохранения времени можно выбрать отдельные страницы для распознавания указав с какой по какую надо распознать. Так же можно распознать текст из pdf на текущей открытой странице выбрав соответствующий пункт в настройках.
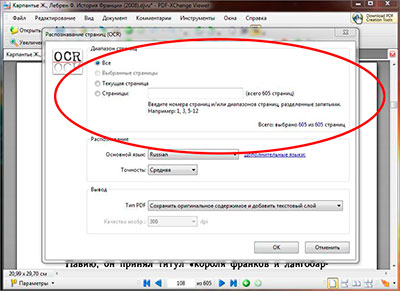
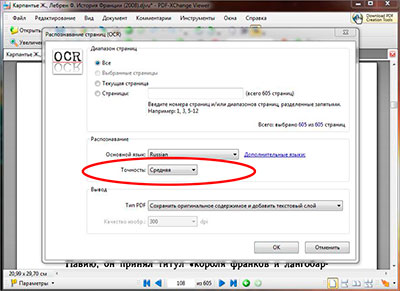
После того как выбран основной язык распознавания и нужные страницы файла, следует указать точность распознавания текста из pdf, их в программе PDF-XChange Viewer три степени: низкая, средняя и высокая. И соответственно, чем выше степень тем лучше будет распознавание, но и времени на обработку в высоком качестве будет потрачено больше чем в низком.
— Регулярная проверка качества ссылок по более чем 100 показателям и ежедневный пересчет показателей качества проекта.
— Все известные форматы ссылок: арендные ссылки, вечные ссылки, публикации (упоминания, мнения, отзывы, статьи, пресс-релизы).
— SeoHammer покажет, где рост или падение, а также запросы, на которые нужно обратить внимание.
SeoHammer еще предоставляет технологию Буст, она ускоряет продвижение в десятки раз, а первые результаты появляются уже в течение первых 7 дней. Зарегистрироваться и Начать продвижение
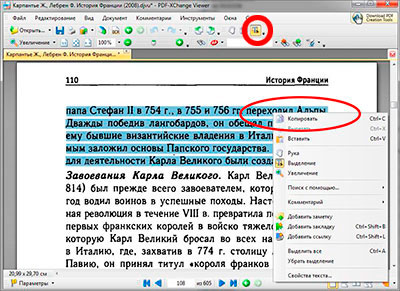
После того как нужный текст из pdf файла распознан, для того что бы его скопировать, следует на панели инструментов нажать на кнопку выделение (она выглядит как квадрат с буквой «Т») и выделить нужные фрагмент текста, а после нажать правой кнопкой мыши и выбрать строку копировать.
Сама же программа PDF-XChange Viewer является вполне хорошим и удобным просмотрщиком pdf файлов с возможностью вставлять комментарии в нужном месте текста, импортом и экспортом файлов данных, настройкой вида текста и окна программы и широкой панелью инструментов.
Распространение: бесплатное.
Операционная система: Windows XP, Windows Vista, Windows 7, Windows 8, Windows 10.
Сайт программы tracker-software.com/product/pdf-xchange-viewer-activex-sdk





